
Self-hosted Diffuser Models vs. Dedicated Content Generation Platform Models For Realistic Generations
A discussion and comparison between known Diffusion Models for realistic image and content generation.

Introduction to Diffusers and AI-generated Content
Diffuser models are generative AI models specialising in audio and visual media such as images, videos, and audio. Different from a Transformer model, which is usually used for text and Natural Language Processing (NLP) in Large Language Models, Diffusers are another type that has gained popularity for their ability to generate media from text prompts and modify existing media to what a user desires.
Current State of Diffuser Models and Competitors
Between the user activity on Reddit, LinkedIn, and Douyin, I’m making this post to compare and express my thoughts on the different AI image generation models I’ve encountered and how they compete for dominance in the current state of the Gen-AI race.
Currently, I’ve noticed that Stable Diffusion is still the King of locally hosted hobbyist-finetuned models. However, as of last week, a new model by Black Forest Labs, known as Flux was released with quality that definitely could make Stable Diffusion sweat in terms of the generation results I’ve seen on Reddit.
Achieving Realism on Self-Hosted Models
I’ve been on a quest recently to achieve photorealism and overall realistic photo shots with generative AI models.
I’m currently working on a YouTube series on consistent character generation and I’m trying to achieve a more realistic result. So, Flux amused me when I saw that their banner image of a crocheted duck was very VERY detailed.
{kind=link}
Out of curiosity, I used Hugging Face Space for FLUX.1-dev, I ended up generating this image:

My Bad Anatomy Realism Classifier model had an extremely hard time differentiating this from a real image, which I think means it is a good sign? The lighting overall looks quite professional and realistic, and I did not specify too many instructions, just a Korean kpop idol in a busy street with a blurred background and some basic features.
Here is a similar prompt but with Stable Diffusion’s latest models:


Compared to the Stable Diffusion XL 1.0 Base and Stable Diffusion 3 Medium models results above, SD3 seems to have a bit of a problem with the clothes and body, but SD and Flux are really close in quality.
Stable Diffusion 3 feels a bit more “airbrushed” as well, with the skin being too smooth and very artificial. Of course, there are checkpoints that do train for more realistic image creation, however, Flux stated that the base model would not be given the ability to be fine-tuned affordably by hobbyists and developers. It seems to not matter that much as the result is still phenomenal.
Today we are trying to talk about self-hosted models versus AI media generation platforms such as Midjourney, Leonardo AI and Copilot. While the self-hosted models provide a budget-friendly option (If you have a strong enough GPU), would paying for generations be actually better for realism? I’m not sure, so let’s dive into this question!
Self-Hosted Models versus AI media SaaS platforms
Self-hosted models are usually a base model by a bigger company but fine-tuned by a hobbyist or developer on their own. This means that they use their own GPUs and resources to create a model checkpoint. A SaaS platform that does AI media generation, on the other hand, has more funding and is a full-fledged company that will finetune and develop models.
Our goal is to compare the model generations and of course, the ability of a platform to generate realistic pictures that could be mistaken for real people.
Models to Compare
So to keep this post relatively short, we will only be comparing:
All these are somewhat accessible to people looking to compare as well and the current comparison test will have us attempt to generate realistic females.
Ease of Use
Right off the bat, Leonardo seems to be the cleanest looking with a simple sign-up and a long list of options including Txt2Img, Txt2Vid, Finetuning, and even access to other models such as SDXL. While it does not give the ability to change inference settings such as CFG or the number of steps, it does give you more than enough models and formatting options to choose from for non-technical users.
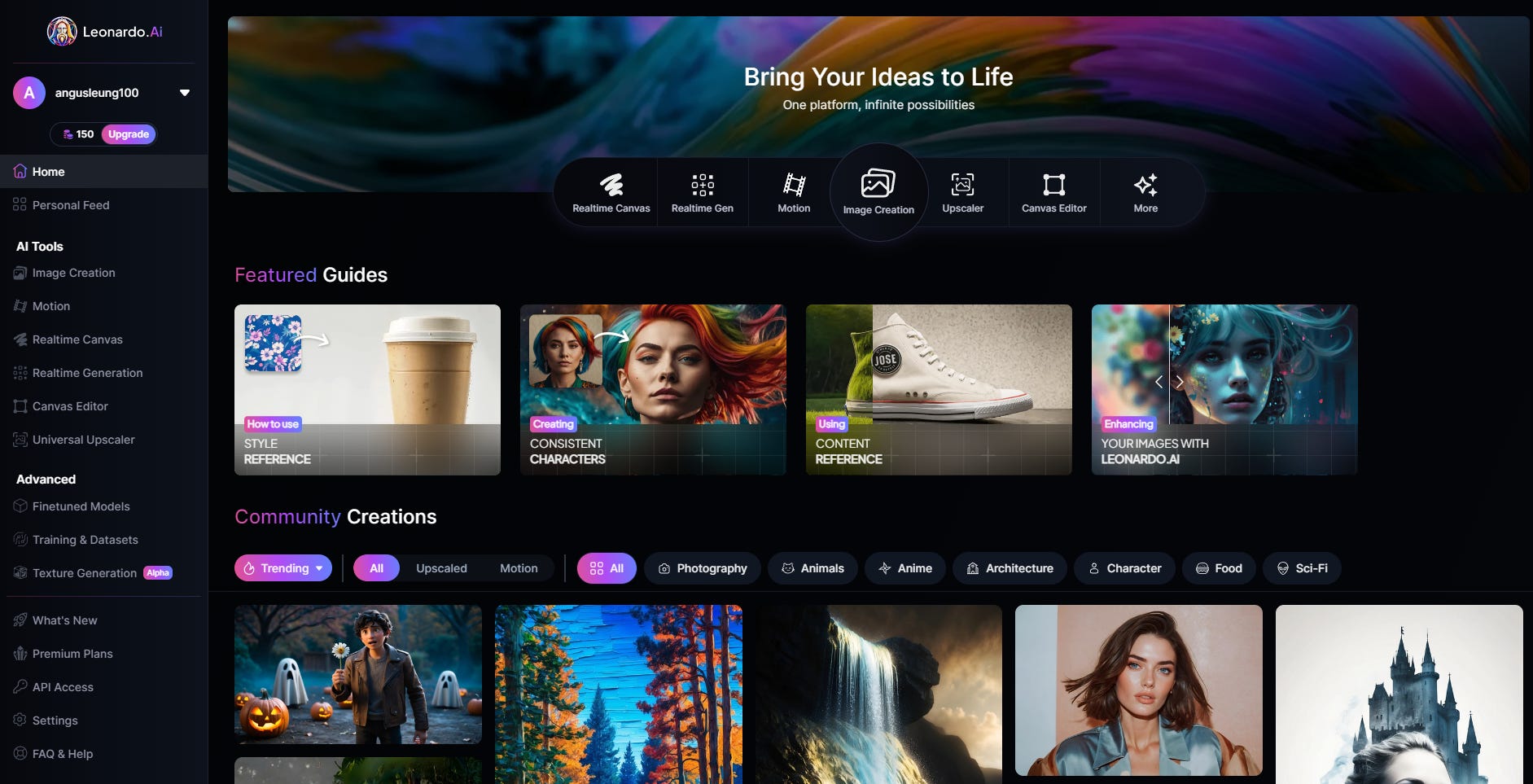
Leonardo let me choose whether I wanted the base model or a model that focused on creating realistic images. Of course, I chose to create realistic images with the “Lifelike Vision” preset running the Leonardo Vision XL model.
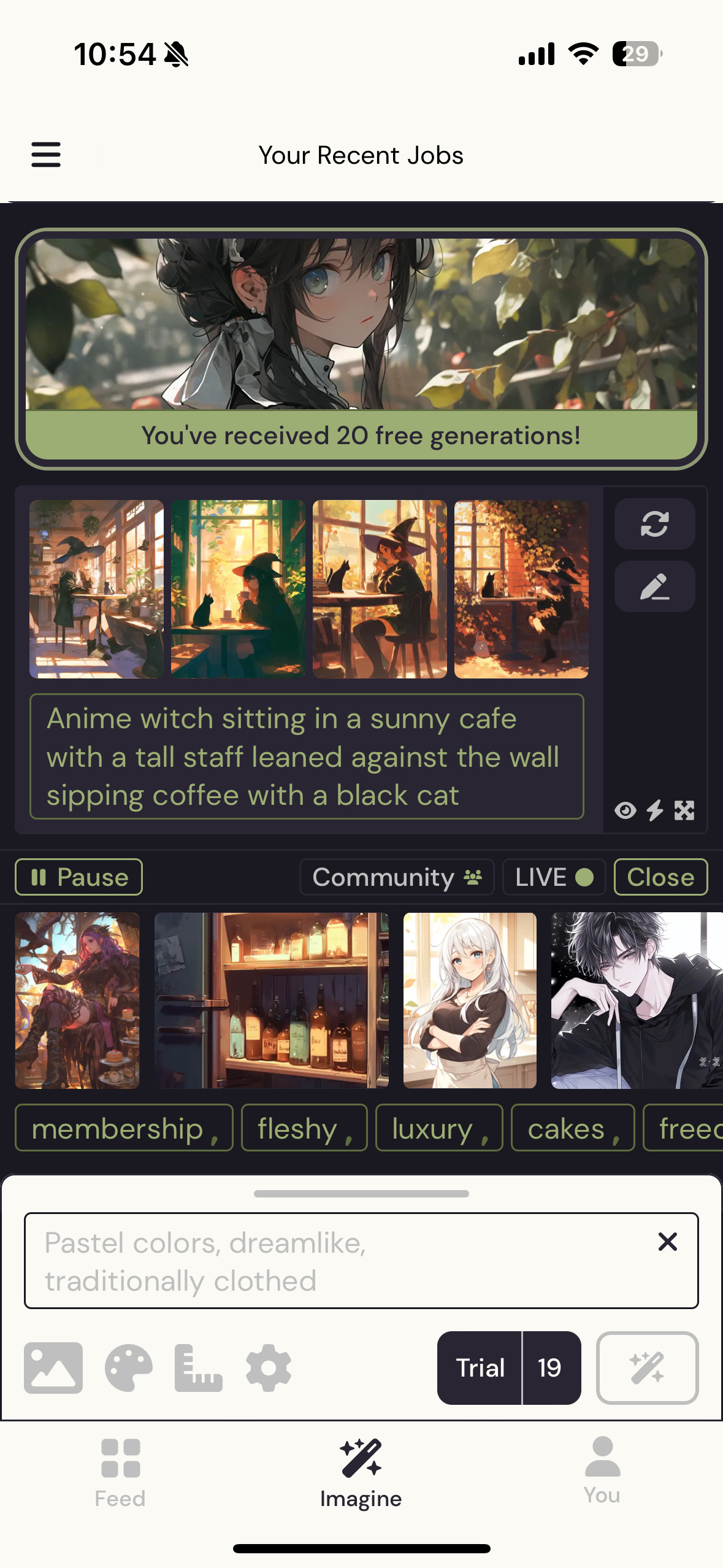
The trial version of Niji is only available on mobile so I had to download the IOS app to try it out. It was very straightforward with a beginner tutorial and even has the option to select the base models for Midjourney such as Midjourney v5 and v6. it did not have as many settings as Leonardo or the self-hosted models but it was very simple to operate.
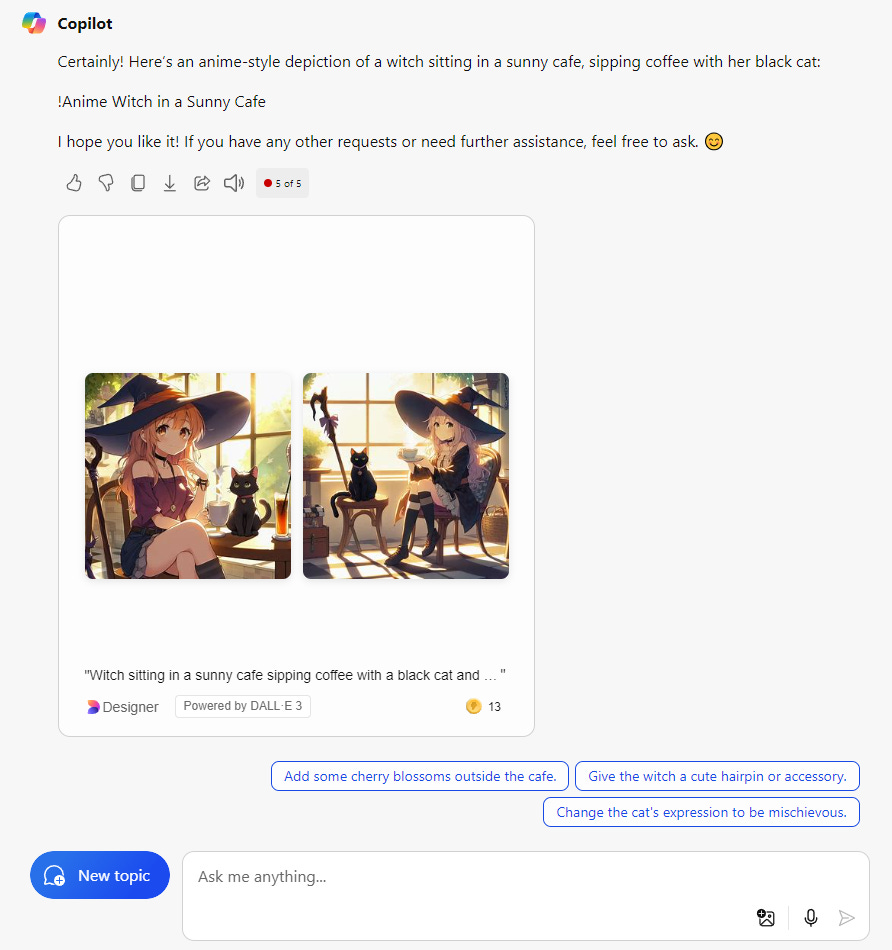
Copilot, the remaining platform for AI image generation, has DALL-E built into the actual chatbot so you cannot change as many settings compared to the other dedicated image generation services. Customization is very basic and images can be edited a little after generation.
It also seems to have a service called Copilot Designer, which removes the Copilot chatbot but replaces it with a simpler UI for generating images:
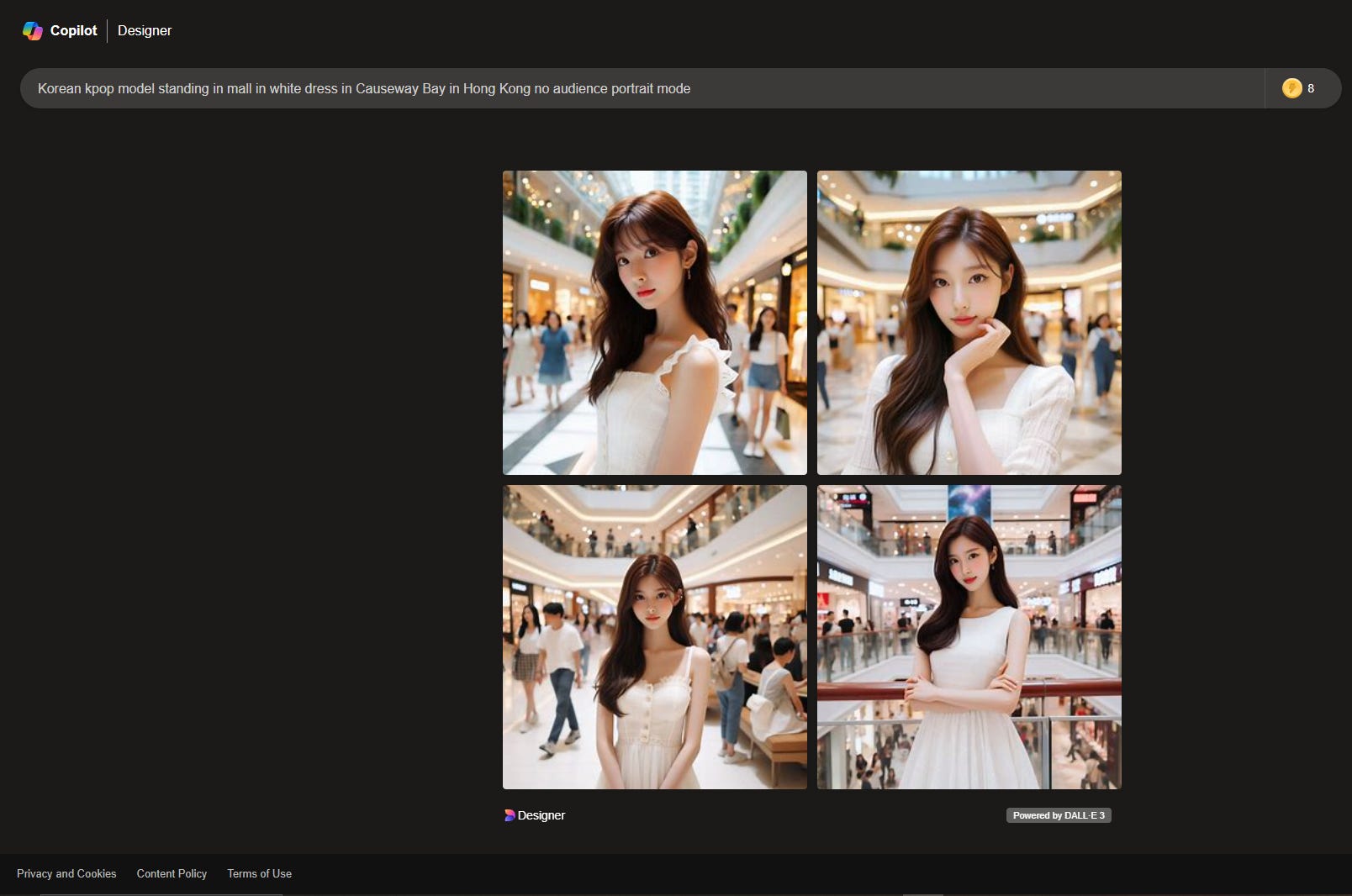
This Copilot Designer is very basic and has no actual ability to edit images. You can crop and put filters later in Microsoft Designer though, but no actual ability to give negative prompts or adjust the model.
Stable Diffusion and Flux, which are base models, actually need scripts and function calls to use. That is why Civitai and Hugging Face have tools to select a model you would like to load and generate in the cloud.
You could also use a UI such as AUTOMATIC1111’s SD Web UI or ComfyUI to run on your local machine, but that does take a little technical knowledge and you would have to download the fine-tuned checkpoints manually to change the generation style.
For generations on Stable Diffusion, I just selected several checkpoints on Hugging Face and Civitai to test out and determine the best checkpoint to use. After spending a decent bit of time installing AUTOMATIC1111 SD Web UI, I was greeted by a lot of sliders and buttons to control generation settings.
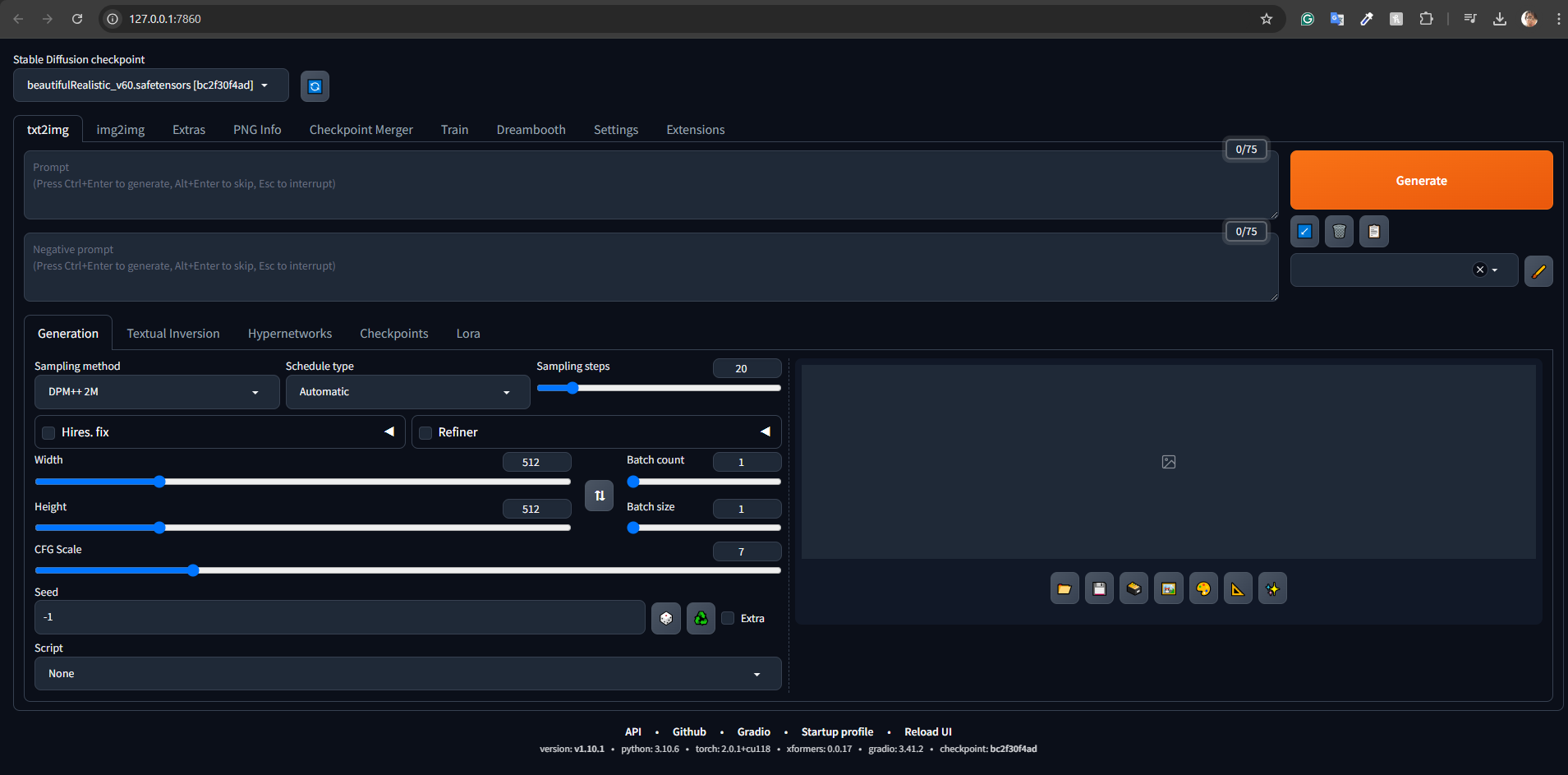
Definitely on the slower end (since you have to host the models yourself) and a higher technical background is needed to control the generation settings.
Since the model for Flux cannot be fine-tuned affordably (for now), by default we must go with the base model. For that, I didn’t even bother trying to find a UI to host Flux locally and used Hugging Face Spaces.
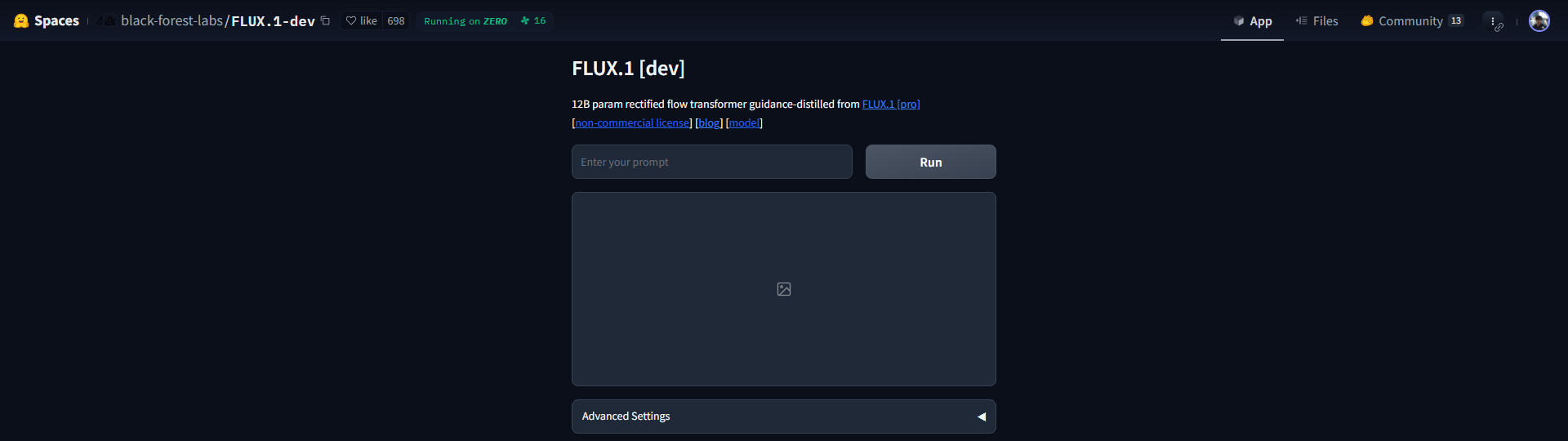
Setting Flux up locally would be similar to Stable Diffusion and ComfyUI already has support for it. It should be the same level of hassle.
Results

From top to bottom, left to right: Stable Diffusion v1.5, Flux 1, Copilot (DALL-E), Leonardo Vision XL, Midjourney v6.
Accuracy and Quality
I think that Copilot definitely feels the most unrealistic, but it has a really good background generation accuracy. When I usually generate people in Stable Diffusion, I end up having to adjust the background generation with LORAs or blur to remove background entities due to deformities.
Even though I tested 3 Stable Diffusion versions, I am personally biased and believe that Stable Diffusion v1.5 was and still is the best supported for realism, as it has a lot of checkpoints already trained for it. As such, I reverted back to SD 1.5 with the Beautiful Realistic Asians v6 checkpoint representing SD for this experiment. However, I would consider Stable Diffusion 3’s base model a good contender for realism if you don’t go too much into detail, as the hair and background eventually give it away:

I feel like Flux 1 had the most realistic lighting, and with filters added for a more grainy feel, could pass off as a real image.
Midjourney v6 and Leonardo Vision XL did really well too on generating background characters and did not mess up on the clothes. Their tones were a bit more dramatic though but it was definitely harder to tell it was AI-generated until you saw the hair and skin textures. I’m not sure how to describe it, but it’s a bit more dramatic and darker than your typical iPhone quality to give it a darker art style.
I’d say that Midjourney v6 looks more realistic if I zoomed in for the face and hair. I did write black hair and did not specify a pose and it did give me its interpretation which was similar to all the other models. Even though I was not able to select the Midjourney art style for realism, the base model stacked up pretty well.
Leonardo was a high-quality generation and definitely was close to real, but I guess I’m just really picky or haven’t surfed Instagram long enough to tell what is real and what could be real nowadays.
Overall thoughts
I don't see that big of a difference in general between the SaaS AI models and the self-hosted models, other than easier onboarding and ease of use. For example, instead of spending a lot of time comparing and downloading checkpoints on Civitai that match your desired art style or generation goals, the SaaS ones just give you presets and well-fine-tuned checkpoints for overall categories.
A platform like Leonardo surprised me with the ability to fine-tune, which opens up a Pandora’s Box of generation opportunity.
Of course, the SaaS AI model platforms do not have as much in terms of generation settings change as the self-hosted models, but for a person who wants to generate high-quality images without much worry about bad anatomy or lacking the hardware to host locally, I definitely would recommend it!